OCR
1 개요
규칙 기반 알고리즘으로 문자를 학습하고 이미지 내에서의 텍스트와 관련 정보를 추출합니다.
2 알고리즘 상세 설명
이미지 전처리 및 문자와 배경을 분리한 뒤, 각 문자들의 정보(모양 및 색상 분포)를 가공하여 학습, 인식합니다.
규칙적이고 고정된 글꼴과 레이아웃을 가진 이미지에 최적화되어있습니다.
-
장점
- GPU 와 같은 고성능 하드웨어 불필요
- Deep Learning 기반보다 빠른 학습, 인식 속도
- 자동 정렬 기능을 탑재하여 한 번에 여러 문자 라벨링 및 학습 가능
- Black, White, All 색상 모두 처리 가능, 학습/인식 간의 교차 가능
- Auto Separation, Auto Scale 지원하여 밝기, 대비, 크기 변화에 강한 내성
- 360도 각도 추청 가능
- 영어, 숫자가 아닌 복잡한 모양의 유니 코드 문자에 대한 처리 가능
- 추출한 문자 각각의 모양과 위치 등의 정보 확인 가능
-
단점
- 문자가 붙어 있거나 과한 손상이 발생할 경우 인식 불가
- Complex 한 이미지에서 문자와 배경 분리가 안될 경우 인식 불가
- 문자 크기가 너무 작을 경우(약 3x3 픽셀) 인식 불가
- 학습한 문자와 글꼴이 상이할 경우 인식 불가
높은 처리 속도를 제공하기위해 내재화된 병렬화 처리 기능을 제공합니다. 멀티스레드, SIMD 를 제공하며 복잡한 설정없이 알고리즘이 자체적으로 판단하여 기본으로 가장 높은 처리속도의 설정으로 바로 실행이 가능하여 손쉽게 사용이 가능합니다, 또한 설비에서 발생할 수 있는 제한된 스레드 사용, 저사양PC의 SIMD사용제한 등에 SetProcessingUnit API를 통해 손쉽게 원하는 리소스 방식으로 사용이 가능합니다.
| 학습 이미지 | 원본 이미지 결과 |
|---|---|
 |
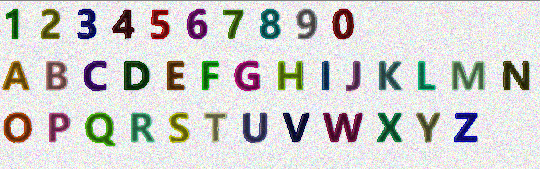 |
색상 반전 | 밝기 변화 |
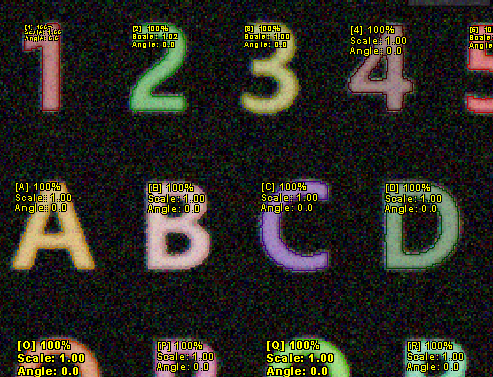 |
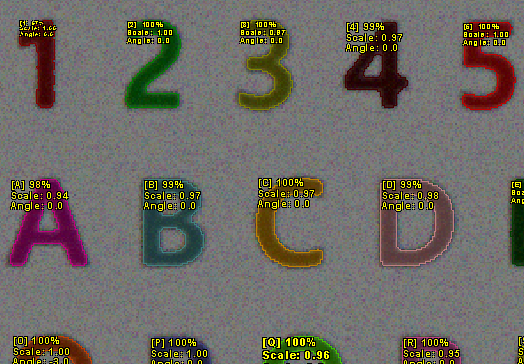 |
스케일 제한 없음, 다양한 각도 지원 | 다른 이미지 결과 1 |
 |
 |
다른 이미지 결과 2 | 다른 이미지 결과 3 |
 |
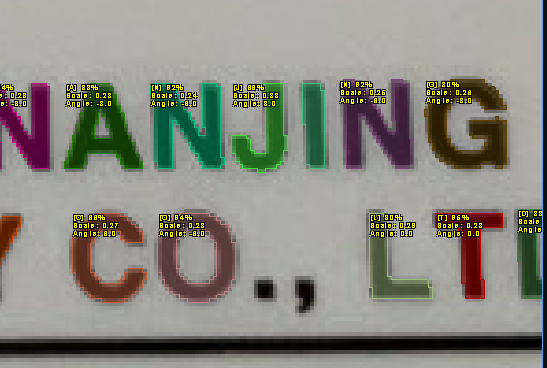 |
3 파라미터 설정 및 사용 방법
[i] 기본적인 동작의 경우, 별도의 파라미터 설정없이 가능합니다.
[ii] 사용자의 최적화된 결과를 제공하기위한 다양한 하이퍼 파라미터를 제공합니다. 해당 파라미터는 설정할 의무가 없으나 설비 혹은 개발에 최적화된 처리속도와 정밀한 결과를 얻기 위해 적절한 파라미터 값을 설정한다면 더 효과적인 결과를 얻을 수 있습니다.
3.1 공통
COCR ocr; // 알고리즘 객체
// 프리뷰 가져오기
CFLImage fliLearn; // 학습 이미지 객체
fliLearn.Load(L"C:/Users/Public/Documents/FLImaging/ExampleImages/OCR/OCR_Learn.flif"); // 학습 이미지 로드
ocr.SetLearnImage(fliLearn); // 학습 이미지 입력
ocr.EnableLearningSeparationMethod(ESeparationMethod_Auto); // 학습 이미지에 Auto Separation 적용
ocr.EnableLearningNoiseReduction(true); // 학습 이미지에 노이즈 감소 적용
const CFLImage* pFliPreview = ocr.GetPreviewImage(true); // 학습 이미지에 대한 프리뷰 이미지 얻기
GetPreviewImage() - 문자와 배경의 분리가 가능해야만 인식 동작을 수행할 수 있습니다. Auto Separation, Threshold Value, Noise Reduction 을 설정하고 Preview 로 이진화 결과를 확인해보세요
EnableLearningSeparationMethod(), EnableRecognizingSeparationMethod() - 이미지에 이진화 방식을 설정합니다.
SetLearningThresholdValue(), SetRecognizingThresholdValue() - Absolute Separation 방식을 사용할 경우 입력값을 기준으로 이진화합니다.
EnableLearningNoiseReduction(), EnableRecognizingNoiseReduction() - 이미지에 노이즈 감소를 적용합니다.
| Learn Image | Preview Image |
|---|---|
 |
 |
Preview 를 보니 문자와 배경 분리가 잘 된 것 같습니다. 색상을 선택하겠습니다.
ocr.SetLearningCharacterColorType(ECharacterColorType_BlackOnWhite); // 흰색 배경에 검은색 문자로 설정
SetLearningCharacterColorType(), SetRecognizingCharacterColorType() - 문자의 색상을 설정합니다. Black On White, White on Black, All 모드 중 선택 가능합니다.
3.1.1 공통 보조 키워드
| Ignore Example |
|---|
 |
학습 또는 인식할 때, 노이즈나 무시하고 싶은 객체가 있을 경우 "!!" 를 이름으로 라벨링하여 처리되지 않게 할 수 있습니다.
3.2 학습
학습할 이미지의 문자를 학습하기 위한 라벨링 작업을 진행하겠습니다.
| Labeling |
|---|
|
다음과 같이 CFLFigure 로 학습할 문자 또는 문자열을 라벨링합니다. Figure Name 으로 문자열의 정답을 입력합니다.
3.2.1 학습 관련 보조 키워드
| Labeling |
|---|
 |
문자열이 붙어 있는 경우 "##" 키워드를 양쪽에 삽입하여 하나의 문자로 취급할 수 있습니다.
ocr.SetLearningWritingDirection(EWritingDirection_LeftToRight); // 왼쪽에서 오른쪽 방향으로 각 문자를 매핑합니다.
ocr.Learn(); // 문자 학습
이제 정렬 방향만 설정하고 학습을 진행해봅시다.
SetLearningWritingDirection() - 학습할 문자의 정렬 방향을 설정합니다.
Learn() - 학습을 진행합니다.
학습이 잘 이루어졌는지 확인해보겠습니다.
const CFLImage* pFliLearned = ocr.GetLearnedImage(); // Learned 이미지 얻기
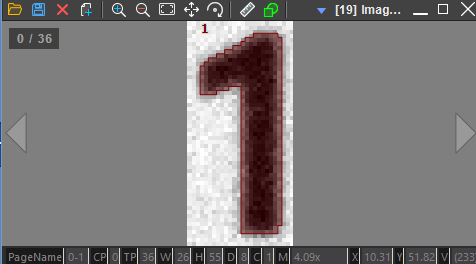
GetLearnedImage() - 학습된 문자 정보가 있는 이미지를 얻습니다. 각 페이지마다 하나의 학습된 문자에 대한 Figure, 매핑 정보를 조회할 수 있습니다.
| Learned Image | Learned Image |
|---|---|
 |
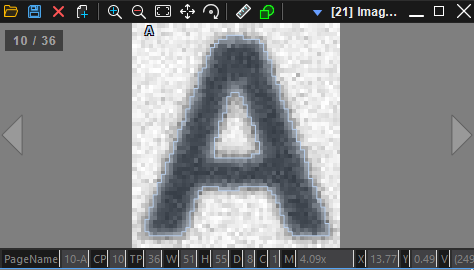 |
원하는대로 학습이 잘 이루어진 것 같습니다. 추가적으로 다음 API 를 호출하여 학습된 문자를 관리할 수 있습니다.
DeleteLearnedData() - 인덱스 번호 또는 문자를 입력하여 학습된 문자를 삭제합니다.
ClearLearnedData() - 모든 학습된 문자를 삭제합니다.
3.3 인식
모든 숫자와 영어 대문자를 학습하였으니 이미지에서 텍스트 정보를 추출해봅시다.
CFLImage fliSource; // Source 이미지 객체
fliSource.Load(L"C:/Users/Public/Documents/FLImaging/ExampleImages/OCR/OCR_Menual_Source.flif"); // Source 이미지 로드
ocr.SetSourceImage(fliSource); // Source 이미지 입력
ocr.EnableRecognizingSeparationMethod(ESeparationMethod_Auto); // Source 이미지에 Auto Separation 적용
ocr.EnableRecognizingNoiseReduction(true); // Source 이미지에 노이즈 감소 적용
pFliPreview = ocr.GetPreviewImage(false); // Source 이미지의 프리뷰 얻기
Learn 이미지와 동일하게 세팅 후 프리뷰를 확인합니다.
| Source Image | Preview Image |
|---|---|
 |
 |
Preview 를 보니 문자와 배경 분리가 잘된 것 같습니다. 다음으로 문자의 각도, 점수의 허용 범위를 설정합니다.
ocr.SetRecognizingAngleBias(0.0); // 기준 각도를 0도로 설정
ocr.SetRecognizingAngleTolerance(30.0); // 허용 범위를 양 옆 30도로 설정
ocr.SetRecognizingMinimumScore(0.7); // 0.7 이상의 Score 로 측정된 객체만 출력
SetRecognizingAngleBias() - 기준 각도를 설정합니다.
SetRecognizingAngleTolerance() - 기준 각도에서 문자가 기울어진 허용 범위를 설정합니다.
SetRecognizingMinimumScore() - 입력값 이상의 Score 로 측정된 문자만을 결과로 받습니다.
인식 동작 실행 후 결과를 받아보겠습니다.
ocr.Execute(); // 인식 동작 실행
int64_t i64ResultCount = ocr.GetResultCount(); // 인식 문자 개수
std::vector<COCR::COCRRecognitionCharacterInfo> vctOcrInfo; // 인식 문자들을 저장하는 벡터
for(int i = 0; i < i64ResultCount; i++)
{
COCR::COCRRecognitionCharacterInfo ocrInfo; // 인식 문자 정보를 담는 객체 선언
ocr.GetResultRecognizedCharactersInfo(i, ocrInfo); // 인덱스마다 인식된 문자 정보 얻기
wprintf(L"Character: %s, Center: (%lf, %lf), Scale: %lf, Angle: %lf, Score: %lf\n", ocrInfo.GetRecognizedCharacter().GetBuffer(), ocrInfo.GetCenterPivot().x, ocrInfo.GetCenterPivot().y, ocrInfo.GetScale(), ocrInfo.f64Rotation, ocrInfo.f64Score); // 인식된 문자의 정보 출력
vctOcrInfo.push_back(ocrInfo); // 벡터에 저장
}
GetResultCount() - 인식된 문자의 개수를 얻습니다.
GetResultRecognizedCharactersInfo() - 입력한 인덱스의 인식 문자 정보를 얻습니다.
인식 문자 정보를 토대로 시각화한 결과입니다.
| Result Image | Result Image(확대) |
|---|---|
 |
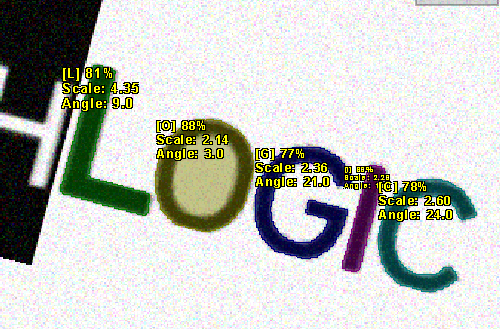 |
"LOGIC" 문자들이 인식되었습니다. 하지만 "FOURTH" 문자들은 인식되지 않았습니다.
Character Color Type 의 디폴트 값이 Black on White 이기 때문입니다. All 모드로 변경 후 다시 실행합니다.
ocr.SetRecognizingCharacterColorType(ECharacterColorType_All); // 모든 색상의 문자를 인식
ocr.SetRecognizingMaximumCharacterCount(11); // 최대 11개까지의 문자를 인식
ocr.Execute();
i64ResultCount = ocr.GetResultCount(); // 인식 문자 개수
vctOcrInfo.clear(); // 벡터 클리어
for(int i = 0; i < i64ResultCount; i++)
{
COCR::COCRRecognitionCharacterInfo ocrInfo; // 인식 문자 정보를 담는 객체 선언
ocr.GetResultRecognizedCharactersInfo(i, ocrInfo); // 인덱스마다 인식된 문자 정보 얻기
wprintf(L"Character: %s, Center: (%lf, %lf), Scale: %lf, Angle: %lf, Score: %lf\n", ocrInfo.GetRecognizedCharacter().GetBuffer(), ocrInfo.GetCenterPivot().x, ocrInfo.GetCenterPivot().y, ocrInfo.GetScale(), ocrInfo.f64Rotation, ocrInfo.f64Score); // 인식된 문자의 정보 출력
vctOcrInfo.push_back(ocrInfo); // 벡터에 저장
}
| Result Image |
|---|
 |
"FOURTHLOGIC" 모든 문자들이 인식되었습니다. 또한 정렬된 문자열로 결과를 받아볼 수 있습니다.
CFLArray<CFLString<wchar_t>> flaText; // N개의 문자열을 담을 Array 객체
ocr.GetResultText(EWritingDirection_LeftToRight, flaText); // 왼쪽에서 오른쪽으로 정렬된 문자열 받기
int64_t i64TextCount = flaText.GetCount(); // 문자열 개수
for(int64_t i = 0; i < i64TextCount; i++)
wprintf(L"%s\n", flaText[i].GetBuffer()); // 문자열 출력
GetResultText() - 입력한 방향으로 정렬된 문자열을 받습니다.
4 학습 데이터 Save & Load 방법 설명
학습한 데이터 파일을 저장 및 불러오기가 가능합니다.
이미 학습한 파일을 저장하여 편리하게 관리할 수 있습니다.
4.1 Save 동작 설명
학습을 진행한 후 해당 학습 데이터 파일을 파일로 저장할 수 있습니다.
Learn 동작을 진행한 이후 저장을 진행 할 수 있습니다.
// 학습 파일 Save 진행
ocr.Save(L"파일 경로 입력"); // 파일 포맷은 .flocr
4.2 Load 동작 설명
저장한 학습 파일을 불러오기가 가능합니다.
저장한 파일을 불러와서 바로 검사 진행이 바로 가능합니다.
OCR 파일이 아닌 Font 파일(.TTF, .TTC) 또한 Load 가능합니다.
COCR ocr2; // 알고리즘 객체
// 학습 파일 Load 진행
ocr2.Load(L"파일 경로 입력"); // 파일 포맷은 .flocr, .TTF, .TTC